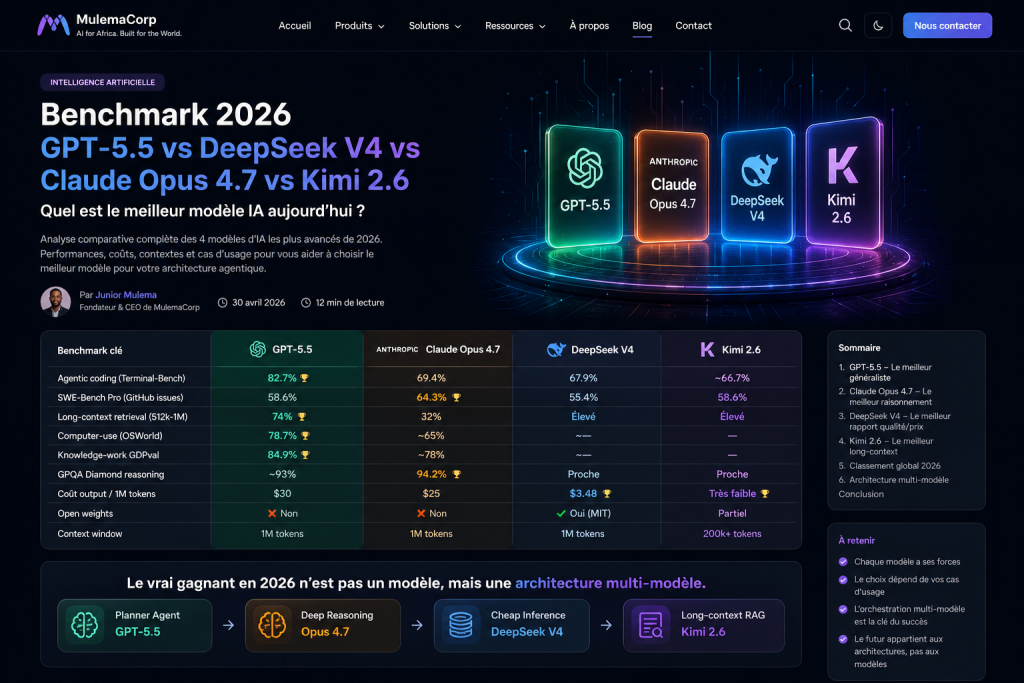
Quel est le meilleur modèle IA aujourd’hui ?
En avril 2026, le marché des frontier LLM est entré dans une nouvelle phase :
ce n’est plus une bataille pour savoir qui est le plus intelligent,
mais quel modèle est le meilleur selon l’architecture agentique ciblée.
Les quatre modèles les plus stratégiques aujourd’hui :
- GPT-5.5 — OpenAI
- Claude Opus 4.7 — Anthropic
- DeepSeek V4-Pro — DeepSeek
- Kimi 2.6 — Moonshot AI
Voici un benchmark comparatif orienté usage réel :
SaaS, RAG, coding, reasoning et optimisation coût.
Tableau benchmark synthétique 2026
| Benchmark | GPT-5.5 | Opus 4.7 | DeepSeek V4 | Kimi 2.6 |
|---|---|---|---|---|
| Agentic coding — Terminal Bench | 🥇 82.7% | 69.4% | 67.9% | ~66.7% |
| SWE Bench Pro | 58.6% | 🥇 64.3% | 55.4% | 58.6% |
| Long-context retrieval | 🥇 74% | 32% | Élevé | Élevé |
| Computer-use OSWorld | 🥇 78.7% | ~65% | — | — |
| Knowledge work GDPval | 🥇 84.9% | ~78% | — | — |
| GPQA Diamond reasoning | ~93% | 🥇 94.2% | Proche | Proche |
| Coût output / 1M tokens | $30 | $25 | 🥇 $3.48 | Très faible |
| Open weights | ❌ | ❌ | 🥇 Oui | Partiel |
| Context window | 1M | 1M | 1M | 200k+ |
Sources : SWE-Bench, Terminal-Bench, GPQA, OSWorld (2026)
GPT-5.5 — le meilleur modèle agentique généraliste
GPT-5.5 est aujourd’hui le meilleur cerveau central pour construire un AI-OS moderne.
Agentic workflows
Leader Terminal Bench :
82.7% contre 69.4% pour Opus 4.7.
- planification multi-étapes supérieure
- meilleure orchestration d’outils
- task chains autonomes
- pilotage agents spécialisés
Long-context reasoning
74% sur retrieval 1M tokens.
- RAG enterprise
- analyse codebase complète
- reasoning documentaire multi-sources
- audit knowledge base
Knowledge-work automation
Score GDPval : 84.9%
- consulting IA
- assistants métiers
- copilotes décisionnels
- production stratégique
Verdict : GPT-5.5 est le meilleur orchestrateur agentique généraliste.
Claude Opus 4.7 — le meilleur modèle reasoning profond
Opus 4.7 domine SWE Bench Pro avec 64.3%.
- correction bugs complexes
- refactor code large scale
- architecture logicielle multi-modules
- raisonnement scientifique avancé
Score GPQA Diamond :
94.2%
- maths avancées
- recherche scientifique
- revue technique senior
- reasoning multi-contraintes
Verdict : meilleur moteur de raisonnement analytique profond.
DeepSeek V4 — le meilleur rapport performance / coût
DeepSeek V4 change l’économie des LLM production-scale.
Coût :
$3.48 vs $30 GPT-5.5
- Terminal Bench : 67.9%
- SWE Bench : 55.4%
Avantages stratégiques
- open-weights
- déploiement on-prem
- souveraineté data
- fine-tuning custom
- infra scale inference
Idéal pour :
- agents entreprise
- cloud souverain
Verdict : meilleur modèle production scale économique.
Kimi 2.6 — le spécialiste long-context économique
- Terminal Bench : ~66.7%
- SWE Bench : 58.6%
Points forts :
- long-context efficiency
- coût faible
- vitesse élevée
- synthèse documentaire
- RAG workflows
Idéal pour :
- agents documentation
- analyse contrats
- knowledge base assistants
- workflow copilots
Verdict : meilleur modèle long-context scalable.
Classement global 2026
🥇 Généraliste
GPT-5.5
🥇 Raisonnement scientifique
Claude Opus 4.7
🥇 Open-source souverain
DeepSeek V4
🥇 RAG scalable
Kimi 2.6
Le vrai gagnant en 2026 : l’architecture multi-modèle
Planner agent → GPT-5.5 Deep reasoning → Opus 4.7 Cheap inference → DeepSeek V4 Long-context RAG → Kimi 2.6
Ce type d’orchestration crée un avantage compétitif durable pour tout AI-OS moderne.
Conclusion
AI orchestration > AI model
Le futur appartient aux architectures capables de router intelligemment :
- raisonnement
- coût
- latence
- sécurité
- context window
- souveraineté
C’est exactement ce que permet un Reasoning Engine multi-LLM moderne.